
Crawl Budget et SEO : Le gros malentendu
Crawl Budget par-ci, Crawl Budget par-là, on a parfois l'impression que l'optimisation du crawl est quelque chose de capital en SEO.
Vraiment ?
Si vous êtes un référenceur, vous pouvez sauter l'introduction en cliquant ici
Définition du crawl
Revenons à la base, qu'est-ce-que le crawl ?
Le crawl représente l'étape où les robots de Google récupèrent le contenu de vos pages.
Il peut s'agir aussi bien de la découverte de nouvelles URL et de la récupération pour la première fois du contenu associé que du millième passage de GoogleBot sur une page qui n'aura pas été modifiée depuis plusieurs années.
Les ressources informatiques allouées à cette étapes sont gigantesques. Google est aujourd'hui capable pour de nombreux sites de crawler une nouvelle page quelques minutes après sa mise en ligne et ceci à l'échelle du web mondial.
L'histoire du crawl
Cela peut sembler quelque chose de normal aujourd'hui mais il faut se rappeler que lorsque cela est sorti en 2007 c'était une révolution ! (cf. Indexation Google en temps réel).
Les vieux référenceurs se souviendront de la Google Dance et aussi et surtout de l’événement "associé" que l'on appelait le "Full Crawl". Qui s'en souvient ?-)
A cette époque, il fallait absolument que ses optimisations soient en production avant cet événement... sinon, il fallait attendre le prochain full crawl. Ces termes sont bien entendu devenus désuets.
Toujours à cette époque, il était plus courant d'utiliser un outil d'analyse de logs type Webalyser qu'un outil analytics à l'aide de tags.
Depuis, Big Daddy et Caffeine sont passés par là, modifiant à jamais notre approche du référencement.
Ces révolutions d'infrastructures techniques mais aussi algorithmiques ont rendu le ticket d'entrée tellement élevé pour un nouvel acteur dans le domaine du Search, que la messe est dite. Seuls Appel, Microsoft, Baidu ou Yandex pourraient espérer avoir une petite chance.
C'est plusieurs dizaines de milliards d'euros qu'il faut désormais investir pour simplement s'approcher de la puissance de calcul, de crawl, de stockage... de Google.
C'est simple, aujourd'hui, il est plus difficile de ne pas se faire crawler que de se faire crawler. C'était bien entendu l'inverse il y a un peu plus de 10 ans.

Définition du crawl Budget
J'y viens, j'y viens, rassurez-vous.
Mais comprendre ce changement de paradigme est indispensable pour comprendre ce que je m’apprête à écrire sur le Crawl Budget.
L’énergie est certainement le plus gros poste de dépense de Google afin d'alimenter ses nombreux data centers. Google n'aime pas le duplicate content car cela gaspille de l'énergie et du "temps machine" pour rien.
Au lieu de crawler et stocker du contenu qu'il connait déjà, il pourrait faire autre chose comme découvrir de nouvelles pages, mettre à jour du contenu ou tout simplement réduire ses dépenses.
Ainsi, Google dispose d’algorithmes pour crawler de manière intelligente. L'objectif est de découvrir un maximum de nouvelles URL, parcourir un maximum de pages connues, le plus rapidement possible en limitant le crawl de pages inutiles !
Le crawl inutile comprend bien entendu le contenu dupliqué mais aussi le fait de crawler des pages qui n'ont pas été modifiées. Pensez notamment aux entêtes "last-modified" et "if-modified-since"...
Google prendra en compte différents critères afin d'optimiser son crawl comme le Pagerank et la périodicité des mises à jour.
Le crawl budget est le "temps machine" que Google a décidé d'accorder au crawl de votre site.
Plus votre site pourra afficher un maximum de pages à Google durant ce temps, plus vous aurez de pages crawlées notamment.
Les algorithmes de Google sont souvent assez intelligents et peuvent repérer d'importantes mises à jour : refonte, changements d'URL, migration vers HTTPS.
GoogleBot remarquera qu'il se passe quelque chose et souhaitera être le premier moteur à proposer vos nouvelles pages à ses utilisateurs mais aussi proposer du contenu à jour et ne pas envoyer vers d'anciens contenus.
Même sans outil d'analyse de logs, il suffit de regarder les courbes peu précises de crawl sur Google Search Console pour se rendre compte du niveau d'excitation du bot.
Il peut donc augmenter d'un coup votre crawl budget dans ce cas de figure.
Crawl et pertinence
Désolé pour cette longue introduction... il est temps d'arriver à l'objet de l'article.
Vous améliorez les performances techniques de votre site, il est devenu ultra rapide => vous avez plus de pages crawlées : Bravo !
Vous analysez les logs ou crawlez votre site, avez découvert un spidertrap et des pages inutiles => vous avez plus de pages crawlées par GoogleBot : Bravo !
Votre site e-commerce comptent 10 000 URL, toutes indexées, : Bravo !
Questions :
- Est-ce-que cela est très important pour votre activité qu'une nouvelle page soit crawlée 5 minutes après sa mise en ligne ? 12H ? 24H ? 48H est suffisant ? Où cela n'est pas vital ?
- Ajoutez-vous sur votre site énormément de contenu chaque jour ?
- Votre site compte-il un nombre très important de pages ?
Si vous avez répondu "non" à ces questions, le notion de "crawl budget" est certainement quasiment inutile pour vous.
Mais vous souhaitez que vos pages se positionnent mieux non ?
Alors est-ce-que le crawl budget est-il un facteur de positionnement ?
Relisons mon dernier article "Comment savoir si un facteur SEO est pris en compte par Google ?" et appliquons la méthodologie.
Une page crawlée deux fois plus qu'une autre est-elle plus pertinente pour une expression clé donnée ?
Mon avis est tranché : NON !
Lorsque toutes vos pages sont indexées et si vous n'êtes pas un site qui ajoutent chaque jour beaucoup de contenus (actualité, petites annonces...), votre crawl budget, et bien... vous pouvez ne plus vous en soucier.
Crawl et ranking, quel est l'avis de Google ?

et aussi
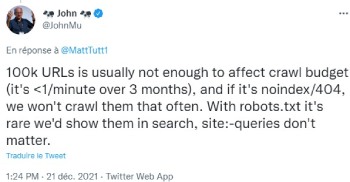
Alors convaincu ?
Maintenant, si j'avais un outil ou une presta d'analyse de logs à vous vendre... je n'aurai peut être pas le même discours 😀




